كيفية تمثيل وترميز النصوص في الحاسوب
كيفية تمثيل ونقل الأحرف باللغات المختلفة والرموز والأرقام في الحواسيب
كيف يتم ترميز النص في الحاسوب؟ لا بد من إيجاد طريقة لتحويل النص لأصفار وواحدات.
– لكننا لن نجري عمليات حسابية على النص!
– نعم صحيح، ولكن كيف سيتم نقل النص عبر الأسلاك (تيار/انعدام تيار)؟ وكيف سيتم تخزينه في أقراص التخزين سواء الممغنطة أو الإلكترونية؟ يجب لهذا تحويل كل شيء بما في ذلك النصوص لأصفار وواحدات (سنتعرف لاحقًا في هذا الكتاب على أقراص التخزين المختلفة وكيفية تخزينها للبيانات).
لإنجاز هذه المهمة يجب أن نعرف ما هو النص. أولًا، يوجد لغات للبشر كما نعلم، ولنبدأ باللغة الإنجليزية. والنص في أصله هو تجميع للأحرف التي تشكل أي لغة، وبالتالي لمَ لا نعطي كل حرف مجموعة محددة من الأصفار والواحدات (عددًا محددًا) وانتهى الأمر؟ مثل أن نعطي الحرف A العدد العشري 1 مثلا و B العدد 2 وهكذا..ويتم تحويل تلك الأعداد المخزنة للأحرف المقابلة لها عندما نريد عرضها على شكل نص. أليست هذه فكرة جيدة؟ نعم إنها حقًا فكرة رائعة!
ولكن ماذا عن الأعداد نفسها؟ كيف سيتم تمثيلها ضمن النص إذًا؟ الأعداد أيضًا تتألف من الأرقام الرئيسية (من 0 إلى 9) في النظام العشري، وبالتالي يمكن أن نعتبر الأحرف الأبجدية + الأرقام المحدودة هذه لتمثيل النصوص والأعداد بحيث نعطي لكل حرف ورقم عددًا محددًا.
ترميز الأحرف
التعبير الأفضل هنا في الحقيقة هو “ترميز المحارف”، ﻷننا سنتحدث عن ترميز الحروف والرموز الرياضية ورموز العملات وغيرها، بالإضافة للأرقام نفسها (0-9). لذا، تعبر كلمة محرف (character) عن الحرف والرمز والرقم.
وكما ذكرنا، يمكن إعطاء كل محرف قيمة عددية معينة، وهذا يعني في واقعه تشكيل معجم، حيث يتم ربط كل محرف بقيمته العددية الخاصة المعطاة، وعندما تضغط أنت على أحد المحارف في لوحة مفاتيحك، يتم النظر للمعجم وتحويله لقيمته الخاصة وتخزينها في الحاسوب (التحويل من محرف لقيمة عددية)، ثم عندما تريد طباعة ذلك المحرف على الشاشة، يتم النظر مجددًا للمعجم وتحويله من قيمته العددية المخزنة إلى الشكل الذي يمثله (التحويل من قيمة عددية لمحرف).
ولكن ما القيم التي نعطيها؟ أو بالأحرى كيف نبني ذلك المعجم؟ الحقيقة طريقة بناء المعجم تتوقف على المساحة التي لدينا، طبعًا من الأفضل دائمًا استخدام أقل مساحة ممكنة، ولكن ما هي أقل مساحة ممكنة؟ حسنًا لننظر ﻷحد المعاجم المقترحة والشائعة والتي تستخدم مساحة 7 بت لكل محرف.. لا ترتعب من مظهره العام، قد يبدو معقدًا، ولكن بتأمل بسيط ستجده أبسط مما يبدو عليه في الوهلة الأولى.
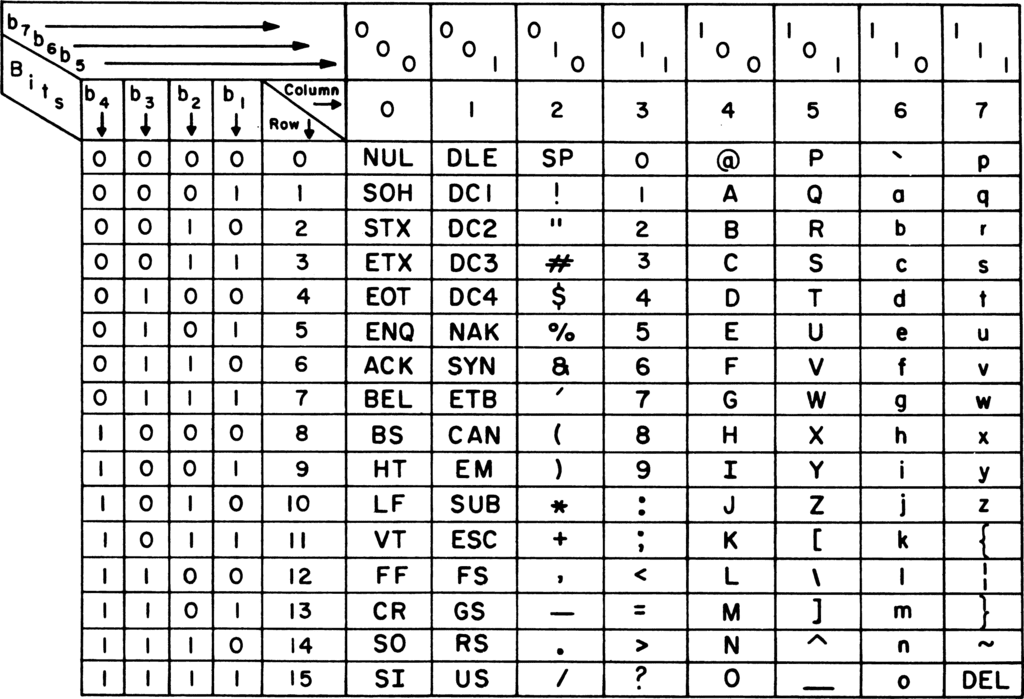
انظر مثلًا للعمود الأول من اليمين، وبتجاهل أول سطرين حاليًا، ستجد الأحرف p ثم q ثم r..وفي آخر هذا العمود بعض الرموز وزر DEL الموجود على لوحة مفاتيحك، حيث يجب تمثيل كل زر ورمز موجود على لوحة المفاتيح(الرموز التي يتم إدخالها مع الزر Shift كذلك). لذا ستجد في الخمس أعمدة التي تليه أي على يساره أيضًا المزيد من الأحرف اللاتينية والرموز. ثم يوجد عمودان يحويان محارف تسمى محارف التحكم (control characters). منها BEL (BELL) والذي يجعل حاسوبك يصدر صوتًا، و ESC (Escape) وغيرهم.
يسمى هذا الترميز (المعجم أعلاه) بـ “أسكي” (ASCII) والاسم هذا اختصار لـ American Standard Code for Information Interchange أي الكود المعياري الأمريكي لتبادل المعلومات، حيث بدأ العمل عليه منذ عام 1961، والجدول الذي تراه هو نسخة محدثة تم وضعها عام 1972.
ولكن لماذا صُمِّم الجدول بهذه الطريقة؟
يوجد عدة أسباب وأمور تمت مراعاتها في تصميم الجدول الذي رأيته في الأعلى، نذكر منها:
- لعرض جميع الاحتمالات للسبعة بت وبالتالي يظهر بشكل واضح أكبر عدد ممكن للمحارف التي نريد تمثيلها، أيُّ زيادةٍ على هذا الجدول تتطلب مساحة إضافية عن السبعة بت. (انظر الآن للأعمدة الأربعة الأولى من اليسار، والتي تمثل أول 4 بت، وقد أُعطوا فعلًا الأسماء b1 أي البت واحد ولغاية b4 أي البت الرابع من العدد، وانظر للسطر الأول الذي يمثل الثلاثة بت المتبقية من العدد ذو السبعة بت، وهم من b5 لغاية b7). مثال: إذا نظرنا للحرف A في الجدول، فيكون العدد الثنائي المقابل له هو البتات b7b6b5b4b3b2b1 يعني 1000001. ويمكن أن نضيف صفرًا على اليسار لنكمل الـ 8 بت.
- تمثيل الأرقام (0-9) (الظاهرين في العمود الخامس من اليمين وبدءا من السطر الثالث) كما يتم تمثيلها بالفعل في النظام الثنائي بالنسبة للأربعة بت الأخيرة، مما يجعل التحويل من النظام الثنائي للعشري سهلا.
- يظهر الفرق بين الأحرف بـ shift وبدون shift (العمود الأول مثلا يبدأ بـ p و q، وإذا ضغطت على shift تحصل على القيم الموجودة في العمود الثالث حيث P كبيرة و Q وهكذا)
- تجميع الرموز مع بعض ومحارف التحكم مع بعض، حيث تظهر محارف التحكم في أول 32 قيمة في جدول أسكي (الظاهرة يسارًا والتي تمثل 0-31 في النظام العشري)
كما تمت مراعاة أنواع الترميز السابقة ﻷسكي، فقد تم وضع الحرف A في الموضع 41hex مراعاةً للمعايير البريطانية.
ولكن ما هي محارف التحكم؟
هي عبارة عن رموز خاصة ليست موضوعة لتشكل معلومات قابلة للطباعة (مثل الأحرف والأرقام والرموز)، وإنما للتحكم بالأجهزة التي تستخدم ترميز أسكي، مثل الطابعات. أو لإعطاء معلومات وصفية عن البيانات المرسلة والتي يتم تخزينها في الأقراص الصلبة. مثلًا، الحرف EOT اختصار لـ End of Text ويُستخدم في الأصل لإعطاء إشارة للحاسوب المستقبِل للبيانات أنه تم الانتهاء من إرسال السجل النصي الحالي، وقد يُستخدم ﻷغراض أخرى مثل إنهاء البرنامج أو العملية.
ليس بالضرورة اليوم أن يكون حاسوبك ونظام تشغيلك يستخدم ترميز أسكي أساسًا، فنحن نتحدث عن أول ترميز شائع، وليس الترميز الشائع اليوم. فقد استُخدم أسكي في البداية عام 1963 في أجهزة تلكس (شبيهة بالفاكس). وقد استُخدم في الحواسيب والوب بشكل شائع حتى عام 2007 حيث ظهرت أنواع ترميز أفضل منه.
فربما لاحظت أن الترميز هذا محدود جدًا؟ أين الأحرف العربية؟ وماذا عن الأحرف الصينية واليابانية والروسية والعبرية ولا أدري كم أبجدية تستخدم البشرية..ألا يجب ترميزها كلها؟
الموضوع فعلًا معقد، ففكر معي، لقد احتجنا 7 بت لترميز بعض الرموز و 26 حرف لاتيني كبير و 26 حرف صغير أي 52 بالمجمل. ولكن إذا أردنا إضافة 28 حرف عربي و 32 حرف روسي و 46 ياباني..إلخ. فكم بت سنحتاج؟!
ولكن لماذا لا يكون لكل لغة ترميزها الخاص؟ ألن يحل ذلك المشكلة؟
قد يحلها بشكل جزئي، ويوجد في الواقع ترميز خاص لليابانية مثلًا، وآخر خاص بالروسية، وترميز الأسكي الذي رأيته للتو الخاص بالإنجليزية. ولكنك تجد أنني أستخدم هنا الأحرف العربية والإنجليزية معًا في نص واحد، فإذا فُسِّر هذا النص وفق ترميز مخصص للغة واحدة فلن تظهر أحرف اللغة الأخرى كما يجب (قد تظهر على شكل إشارات استفهام أو طلاسم..وأعتقد أنك رأيت ذلك سابقًا في مكان ما).
لقد ذكرت لك أن ترميز أسكي يستخدم 7 بت فقط، إلا أن الحواسيب صُممت منذ البداية لتعمل مع وحدات من المساحة تكون 2 أس كذا، أي مضاعفات الاثنان، لذا توجّب إضافة 0 ليسار قيم الأحرف المرمزة بترميز أسكي لتصبح 8 بت (واحد بايت). وسمح كذلك هذا البت الزائد بإضافة أحرف جديدة، حيث تتسع الـ 7 بت لـ 127 محرف، بينما يوجد 128 خانة إضافية إذا استخدمنا ذلك البت الثامن. وشرع صانعوا الحواسيب مثل أبل وميكروسوفت و IBM بوضع تراميز موسعة للأسكي (Extended ASCII) عبر إضافة رموز وأحرف إضافية من اللغات الأوربية مثل Ä و Á وغيرها (مستغلين ذلك البت الثامن). وأنشأ كل مصنّع نسخ موسعة كثيرة خاصة به، وكل نسخة غير متوافقة مع الأخرى، وبدأت الفوضى، خاصة عند ظهور الوب وتبادل النصوص بين الأجهزة، فإذا تم إرسال النص المرمّز وفق ترميز معين لجهاز آخر وفُسّر وفق ترميز آخر، فلن يتم عرض النص بالشكل الصحيح. وسنرى الحل المقترح بعد قليل.
أحد تلك التراميز الموسعة هو ترميز CP-1252 والذي يدعى أيضًا windows-1252 بسبب استخدامه بشكل واسع في نظام ويندوز. يوسِّع هذا الترميز ترميز أسكي، حيث يستخدم أول سبعة بت كما يستخدمها أسكي (وبالتالي النصوص المُرمّزة وفق أسكي سيتعرف عليها بدون مشاكل) ويضيف لها بت إضافي، أي يستخدم 8 بت، لترميز الأحرف الإضافية الموجود في اللغات الأوربية مثل الإسبانية والفرنسية والألمانية، مثل الحرف ñ والحرفÜ وما إلى ذلك.
إذًا، استطاع الترميز الأخير توسيع ترميز أسكي وترميز باقي اللغات الأوربية عبر استخدام بت واحد إضافي أي 8 بت (وهذا يشكل بالمجمل بايت byte واحد). وهذا يعني في النظام العشري استخدام الأعداد من 0 إلى 255.
أما في الترميزات المتعلقة باللغات الكورية والصينية واليابانية فيتم استخدام 2 بايت أي 16 بت، وهذا يعني في النظام العشري المجال 0–65535 (على اعتبار استخدام الأعداد الموجبة فقط؛ أي عدم تخصيص بت للإشارة). وهي ترميزات مخصصة للغة معينة، أي لا يمكن أن تمثل الأحرف الإنجليزية مثلًا، ﻷنها تستخدم نفس القيم لإعطاء معاني أخرى خاصة بأحرفها، ومختلفة عما تعطيه قيم أسكي أو الترميزات الأخرى. مثال على ذلك: العدد 241 في النظام العشري يمثل الحرف الروسي Я وفق ترميز koi8-r، ونفس العدد يمثل الحرف اليوناني ώ وفق ترميز Mac Greek.
وقد عملت الترميزات المخصصة لكل لغة بشكل جيد قبل تطور الإنترنت، حيث احتاج كل شخص للعمل على حاسوبه فقط، وحيث يكون هو مؤلِّف النص، ويعيد فتح النص الذي كتبه بنفس البرنامج الذي يستخدم نفس الترميز، لذا لا يوجد أي مشكلة.
ولكن مع تطور الإنترنت، تخيل أن صديقك الكوري قام بإرسال رسالة لك بالبريد الإلكتروني (رسالة باللغة الإنجليزية مثلًا)، واستخدم ترميز معين غير الذي تستخدمه أنت في جهازك، عندها سيظهر لك نصًا عجيبًا، مؤلف من إشارات استفهام، أو أحرف غريبة تشكل طلاسم وشيفرات وراثية! :) ولا بد أنك رأيت مثل ذلك من قبل.
لنتذكر سبب المشكلة؛ مشكلة الخطأ في تفسير النص. حيث قام الشخص بكتابة نص باستخدام ترميز معين (معجم معين يعطي لكل حرف عدد مخصص له) وقد تم حفظ تلك الأعداد ونقلها إليك بالشكل الصحيح، فالأعداد التي تمثل النص والتي حُفظت بجهازه، قد تم نقلها نفسها لجهازك بدون أي خطأ، الخطأ الذي يحدث الآن هو أنك تستخدم ترميز (معجم) آخر لتفسير تلك الأعداد وعرضها بشكل نص، مما يؤدي لتفسير خاطئ للأعداد وإعطاء أحرف غير المتوقعة. وحل هذه المشكلة لا يستدعي أبدًا أن تطلب إعادة إرسال الملف النصي، فالمعلومات لديك بالفعل، بل أن تستخدم الترميز الصحيح لتفسير الملف.
والآن وبسبب وجود الإنترنت، نحتاج لترميز موحد لعرض النصوص على كل الأجهزة وفق نفس الترميز، وهذا يتطلب منا وجود ترميز يفسر كل الأحرف في كل اللغات، وذلك سيحل أيضًا مشكلة ترميز النص الذي يحوي بداخله كلمات من أبجديات مختلفة، مثل ما أفعل أنا هنا من خلال استخدام الأحرف العربية والإنجليزية في نفس النص.
ولهذا وُجد ترميز Unicode، اختصارًا لـ Universal code أي الكود العالمي، وهو ما نطلبه بالضبط – ترميز مُوحَّد لكل اللغات.
يمثل هذا الترميز كل الأحرف بكل اللغات! وذلك عبر استخدام مساحة 4 بايت (32 بت) لكل حرف! (لقد اتسعت جميع الأحرف التي تم تمثيلها في 21 بت فقط، ولكن الحواسيب تعمل بشكل أفضل مع المساحة التي تكون من مضاعفات العدد2 (2-4-8-16-32-64..) وكوننا تجاوزنا الـ 16 فالأفضل استخدام مساحة 321، وكذلك لإمكانية إضافة أحرف جديدة في المستقبل، مثل الصور الرمزية emojis الجديدة التي تظهر بين الحين والآخر. وهذا يعني أننا نضيف أصفارًا على اليسار في المساحة المتبقية غير المستخدمة)
لنتوقف هنا ونفكر في الأمر. تصور أننا نريد كتابة نصًا بالإنجليزية، النص نفسه كان يتطلب 7 بت وفق ترميز أسكي (مع 0 إضافي على اليسار لنشكل بايت – أي 8 بت)، والآن نفس النص سيتطلب 4 أضعاف تلك المساحة، أي الملف النصي (الإنجليزي) سيأخذ بذلك أربعة أضعاف المساحة على القرص الصلب وفق هذا الترميز، وهذا سيبطئ عملية إرسال واستقبال الملف عبر الإنترنت (سيأخذ مجددًا أربع أضعاف المدة التي كان يحتاجها مع ترميز أسكي). أليست هذه مصيبة! نعم لقد وحدنا الترميز ولكن الحجم أصبح كبيًرا جدًا.
لقد وُضع ترميز Unicode بحيث يكون متوافق مع أسكي، بسبب الاستخدام الواسع ﻷسكي في ذلك الوقت، وهذا يعني أنه يعطي نفس القيم للمحارف الموجودة في أسكي، وبالتالي يمكن عرض النصوص المرمزة بأسكي في هذا الترميز بدون مشاكل، ولكن الحجم أكبر كما ذكرنا، أي أن الحرف A مثلًا سيأخذ القيمة 01000001 في أسكي، ونفس القيمة في يونيكود ولكن مع إضافة أصفار على اليسار لإكمال الـ 32 بت:
\[00000000 00000000 00000000 01000001\]هل رأيت الأصفار على اليسار، والتي يتجاوز عددها الثمانية؟ تتعامل الكثير من أنظمة التشغيل اليوم مع الثمانية أصفار المتعاقبة والمستقبَلة من جهاز آخر على أنها إشارة لانتهاء الإرسال، وبالتالي تتوقف عندها عن الاستقبال، وهذه مشكلة أخرى.
ولحل مشكلة المساحة الضائعة، تم اقتراح الترميز التالي، والذي يستخدم بشكل رئيسي 16 بت فقط، وبناء على ذلك سُمي الترميز السابق بـ UTF-32 (32-bit Unicode Transformation Format)
والترميز المقترح الذي سنتحدث عنه أُعطي الاسم UTF-16.
تُمثَّل القيم المعطاة من قبل ترميز يونيكود بالشكل U+ ثم القيمة وفق نظام العد الست عشري (hexadecimal)، وبهذا يُعطى مثلا حرف الـ A القيمة U+0041 ويُعطي الرمز & القيمة U+0026 وهكذا (انظر لبعض الرموز وترميزها هنا https://home.unicode.org/ ويمكنك البحث هنا عن ما تشاء، فيمكن أن تكتب أي حرف أجنبي أو عربي، أو تكتب اسم رمز معين مثل heart مثلا لتظهر لك كل رموز القلب مع قيمها https://www.fileformat.info/info/unicode/char/search.htm ). وتسمى تلك القيم بـ code points وتكون جميع الرموز واﻷحرف تحمل القيم الواقعة في المجال بين U+0000 و U+10FFFF، أي 21 بت حد أقصى. وتقسم هذه القيم لـ 17 مستوى، حيث يشمل المستوى الأول جميع الأحرف المستخدمة في يومنا هذا، ويسمى Basic Multilingual Plane (BMP) وهو في المجال U+0000 إلى U+FFFF أي أول 16 بت.
لذا وكما رأيت، يمكن تمثيل كل الأحرف المستخدمة في لغات اليوم في 16 بت فقط، بل وحتى الصور الرمزية (emojis) ورموز الرياضيات والعلوم والموسيقا، وهذا مايفعله الترميز السابق UTF-32، أما المساحة الإضافية فهي للأحرف الأخرى الأقل استخدامًا (أو نادرة الاستخدام)، والتي تشمل مثلا ما يسمى بالعربية الشمالية القديمة (Old North Arabian) وهي لغة أنا شخصيًا لم أسمع بها من قبل، انظر مثلا لعينة من أحرفها2:

حيث يمثل أول حرفين في الأعلى الحرف راء (على اليسار) والحرف تاء (على اليمين). وها نحن عرب ولا نستخدم هذه اﻷحرف أبدًا وفق ما أعلم، فلماذا نزيد المساحة من أجل أحرف لا تُستخدم إلا نادرًا. طبعًا الأحرف أعلاه مجرد مثال وهناك الكثير أيضًا من الأحرف الخاصة بلغات أخرى ونادرة الاستعمال أيضًا. (يمكنك الاطلاع على قائمة اللغات المشمولة في ترميز يونيكود في الصفحة التالية: https://en.wikipedia.org/wiki/Plane_(Unicode)
ولا تنس أن أكبر عدد عشري يمكن تمثيله في 16 بت هو 65535، ومقابله في 32 بت هو 4294967295، وبالتالي الفرق بينهما فرق شاسع. لذا تم اقتراح ترميز UTF-16 والذي يستخدم مساحة متغيرة في الواقع، أي ليست مساحة ثابتة على 16 بت، وإنما بشكل رئيسي وافتراضي يتم استخدام 16 بت والتي تشمل الأحرف المستخدمة اليوم، وهي نفسها المعرفة في UTF-32، وتزداد المساحة في حال تم استخدام أحرف إضافية ذات القيم الواقعة ضمن المساحة الإضافية الزائدة عن 16 بت.
– هل قلت تزداد المساحة؟ ماذا يعني هذا؟ وماذا يعني أصلًا “مساحة متغيرة”؟
سؤال جميل، وأنت حقًا شخص عبقري ﻷنك دائمًا تسأل أسئلة في محلها :)
بالنسبة للمحارف التي لا تتطلب أكثر من 16 بت فيتم تمثيلها كما هي (ضمن 16 بت)، مثل الحرف A ذو القيمة (U+0041) في يونيكود. والذي يصبح بالشكل
\[0000000001000001\]أما بالنسبة للأحرف (المحارف) التي تتطلب أكثر من 16 بت، فيتم إعطاؤها مساحة 32 بت. أي أن المساحة في هذا الترميز تكون إما 16 أو 32 بت.
ولكن الأمر ليس بهذه السهولة، فالبرنامج لديك والذي يفسر ترميز UTF-16 سيعتبر افتراضيًا أن كل 16 بت تشكل محرف، ويتم التفسير على هذا الأساس، وبالتالي لو قمنا بترميز المحارف التي تتطلب أكثر من 16 بت بشكل عادي أيضًا ضمن 32 بت، فسيقوم المفسر مجددًا بتفسير كل 16 بت على حدة، وسينتج لدينا شيء مختلف.
إذًا كيف سيتعرف البرنامج الذي تعمل عليه والذي يفسر ترميز UTF-16 على المحارف التي تستخدم 32 بت ليفسرها بشكل مجتمع وليس كل 16 بت على حدة؟
يتم هنا وضع سابقة خاصة للمحارف ذات القيم الأكثر من 16 بت، وهي 110110، وبالتالي يقرأ المفسر الأرقام (كل 16 بت مع بعض، كالعادة) وعندما يصل لل 16 بت التي تبدأ بهذه السابقة، فسيفهم المفسر أن عليه أن يكمل لغاية الـ 32 بت ليفسرهم بشكل موحد.
دعنا هنا نتعرف أكثر على عملية التحويل إلى ترميز UTF-16 بالنسبة للمحارف التي تتطلب أكثر من 16 بت. خذ نفسًا عميقًا هنا…تأكد أنك فهمت ما قرأته أعلاه..ثم أكمل.
يتم كما ذكرنا تقسيم المساحة (في الأعداد التي تتطلب أكثر من 16 بت) لجزأين، كل جزء عبارة عن 16 بت، الجزء الأول يسمى High Surrogate أي البديل الأعلى، والجزء الثاني يسمى Low Surrogate أي البديل الأدنى. يبدأ البديل الأعلى كما ذكرنا بالسابقة 110110 ويبدأ البديل اﻷدنى بالسابقة 110111، أي بالشكل:
\[110110xxxxxxxxxx \quad 110111xxxxxxxxxx\]وبقي لدينا مساحة عشرة بت في كل جزء. والآن يتم أخذ الكود الذي يعطيه يونيكود عامة، ويتم طرح 10000hex منه. دعنا نفعل ذلك مع رمز البيضة 🥚 والذي يحمل القيمة U+1F95A في يونيكود (أي أكثر من 16 بت)، والآن لتحويلها لـ UTF-16:
\[1F95A_{hex} − 10000_{hex} = F95A_{hex}\]لاحظ أن عملية الطرح هذه أنتجت نفس العدد دون الـ 1 في البداية. نقوم الآن بتحويل الناتج للنظام الثنائي ولـ 20 خانة (عدد الخانات اللازمة لملؤها في الأعلى) فينتج:
\[0000111110 0101011010\]والآن خذ العشرة بتات على اليمين وضعها في تتمة الجزء الأيمن (البديل الأدنى) من تمثيل UTF-16 والعشرة على اليسار في تتمة الجزء الأيسر أو البديل الأعلى:
\[\textcolor{blue}{110110}0000111110 \quad \textcolor{blue}{110111}0101011010\]ويمكن تمثيل ذلك (العدد الأخير بالكامل) في النظام الست عشري بالشكل: D8 3E DD 5A وانتهى.
قد تسأل: لماذا يكون تمثيل اليونيكود (أي الكود بوينت U+1F95A) والذي يَستخدم النظام الست عشري مختلف عن التمثيل الست عشري في ترميز UTF-16؟
نعم لأنه كما ذكرنا، يستخدم ترميز UTF-16 سوابق في حالة تطلب الحرف أكثر من 16 بت، لذا فالقيمة تختلف.
هل رأيت السابقة في البديل الأعلى والسابقة في البديل الأدنى؟ كوننا نستخدمهم ليدلوا على هذا المعنى الخاص بكونهم سابقات، أي ليتم قراءة جزأين معًا، فهذا يعني أنه لا يمكن لتلك السابقات أن تكون أبدًا بدايةً لأي محرف (ذو 16 بت)، يعني لا يوجد أي محرف تكون قيمته تبدأ بهذه السابقة، وإلا لن تحصل تلك السابقات على المعنى المطلوب ولن نحصل على التفسير المطلوب. وللقيام بذلك يترك ترميز UTF-16 القيم فارغة في المجال بين D800hex و DFFFhex، وهي كل القيم الممكنة (ذي ال 16 بت) التي تبدأ بالسابقات المخصصة. ولهذا السبب تجد مجالًا فارغًا من الخانات غير المستخدمة (وغير المتاحة للاستخدام) في ترميز UTF-16 (في حين أن القيم التي قبلها والتي بعدها تكون مستخدمة بالفعل أو متاحة للاستخدام). انظر للصورة التالية على ويكيبيديا https://en.wikipedia.org/wiki/UTF-16#/media/File:Unifont_Full_Map.png ، يمكنك تكبيرها لترى كل الأحرف المرمزة في ترميز UTF-16 وسترى مجالًا فارغًا قريبًا من النهاية في الأسفل، وهو المجال غير المتاح الذي ذكرته لك.
{kind=link}
والآن قد تسأل عن سبب طرحنا لقيمة يونيكود من \(10000_{hex}\) في الخطوة الأولى للتحويل لترميز UTF-16. والسبب بسيط، ﻷننا لا نريد الحصول على قيمة تتطلب أكثر من 20 بت.
يُستخدم ترميز UTF-16 في نظام ويندوز وفي الرسائل النصية القصيرة SMS وبالأخص التي تحوي على صور رمزية (emojis). وهو غير متوافق مع ترميز أسكي (الأحرف تأخذ قيم في أسكي غير التي تأخذها هنا) ولا يُستخدم في الوب (إلا في صفحات قليلة جدًا جدًا). إذا كنت ممن استخدم (أو يستخدم) الرسائل النصية القصيرة SMS على شبكة الهاتف المحمول، فلا بد أنك عرفت الآن سبب احتساب عدد كلمات أقل في اللغة العربية على أنها رسالة واحدة، في حين أن الرسالة الواحدة يمكن أن تتسع لكلمات أكثر في اللغة الإنجليزية. حيث تتطلب الأحرف العربية أرقامًا (واحدات وأصفار) أكثر وفق الترميز هذا. (أي أن الأحرف الإنجليزية أُعطيت قيم عددية أصغر من القيم التي أعطيت للأحرف العربية).
ولقد علمنا إلى الآن أن ترميز UTF-32 يتطلب دائمًا مساحة ثابتة وهي 32 بت، وUTF-16 يتطلب مساحة متغيرة، وهي إما 16 بت أو 32 بت.
ووُضِع أخيرًا الترميز الأكثر شيوعًا اليوم على الإنترنت، وحش التراميز وقاهر الأسكي وما بعدها..إنه UTF-8، والذي يستخدم أيضًا مساحة متغيرة، إما 8 أو 16 أو 24 أو 32 بت (أي من 1 لـ 4 بايت). علمًا أن الأحرف العربية تتطلب دائمًا 16 بت وفقًا لهذه التراميز جميعًا.
كيف يعمل UTF-8؟
الحرف (المحرف) الذي يتطلب بايت واحد، يُسبق بصفر، مثل الحرف A (U+0041) والذي يكون بالشكل:
\[\textcolor{blue}{0}1000001\]وهذه هي قيمة الحرف A بالضبط في ترميز أسكي. أي أن هذا الترميز متوافق مع ترميز أسكي ويمكنه عرض النصوص التي كُتبت وفق ترميز أسكي بدون أي مشاكل. (بينما يكون UTF-32 و UTF-16 غير متوافقين مع أسكي) في حالة الأحرف التي تتطلب اثنان بايت، فيُسبق البايت الأول بواحدان (للدلالة على وجود بايتان يعبران عن هذا الحرف) ثم صفر، ويسبق البايت الثاني بـ 10، مثل الحرف باء العربي (U+0628):
\[\textcolor{blue}{110}11000 \quad \textcolor{blue}{10}101000\]والأحرف التي تتطلب ثلاثة بايت، البايت الأول يُسبق بـ ثلاث واحدات ثم صفر، والبايتات اللاحقة تُسبق بـ 10 كذلك. مثل الحرف الصيني 蛋 (U+86CB):
\[\textcolor{blue}{1110}1000 \quad \textcolor{blue}{10}011011 \quad \textcolor{blue}{10}001011\]وبالنسبة للأحرف التي تتطلب ثلاثة بايت، فيُسبق البايت الأول بـ ثلاث واحدات ثم صفر، والبايتات اللاحقة تُسبق بـ 10 كذلك. مثل الحرف الصيني 蛋 (U+86CB):
\[\textcolor{blue}{11110}000 \quad \textcolor{blue}{10}011111 \quad \textcolor{blue}{10}011001 \quad \textcolor{blue}{10}000010\]وأخيرًا، بالنسبة للأحرف التي تتطلب أربعة بايت، يُسبق البايت الأول بأربع واحدات وصفر، وتُسبق البايتات الثلاثة الأخرى بـ 10. مثل رمز الابتسامة (U+1F642):
\[\textcolor{blue}{11110}000 \quad \textcolor{blue}{10}011111 \quad \textcolor{blue}{10}011001 \quad \textcolor{blue}{10}000010\]وإذا سألتني عن طريقة التحويل فهي بسيطة جدًا ومباشرة. الحرف الأخير مثلًا هو U+1F642 أي بالتحويل للنظام الثنائي يكون (إذا تجاهلت السابقات أعلاه، فستجد نفس العدد الثنائي التالي):
\[1F642_{hex} = 11111011001000010_{bin}\]ونعلم أنه لدينا وفق ترميز UTF-8 سبعة بت في حالة استخدام بايت واحد (حيث أول بت من اليسار يجب أن يكون صفر دائمًا). وفي حالة استخدام بايتان فيكون لدينا مساحة 5 بت في البايت الأول (بسبب وجود السابقة 110) و6 في البايت الثاني (حيث السابقة 10)، .وهكذا. الحرف أعلاه مؤلف من 17 بت، ولن يتسع في 3 بايت، حيث المساحة المتاحة هي 4+6+6 ويساوي 16. لذا يجب استخدام أربعة بايت، ويتم وضع السابقات ثم توزيع الأرقام كما هي من اليسار لليمين. علمًا أن المساحة المتاحة في أربعة بايت هي 3+6+6+6 أي 21، ولدينا 17 فنكمل أصفار من جهة اليسار:
\[0000 \quad 11111011001000010\]ثم نوزع أرقام العدد كما تعلمنا:
\[\textcolor{blue}{11110}xxx \quad \textcolor{blue}{10}xxxxxx \quad \textcolor{blue}{10}xxxxxx \quad \textcolor{blue}{10}xxxxxx\] \[\textcolor{blue}{11110}000 \quad \textcolor{blue}{10}011111 \quad \textcolor{blue}{10}011001 \quad \textcolor{blue}{10}000010\]وهو نفس ما كتبناه في الأعلى.
لقد رأينا أن استخدام مساحة متغيرة يوفر من استخدام المساحة عمومًا، بينما المساحة الثابتة كما في UTF-32 تستهلك أحجامًا إضافية لا حاجة لها في الغالب (في الأحرف التي لا تتطلب). ولكن هل للمساحة الثابتة ميزة غير موجودة في المساحة المتغيرة؟
نعم. يمكن معالجة النص ذو الترميز الذي يستخدم مساحة ثابتة بشكل أبسط وأسرع، فإذا أردنا عرض الحرف الخامس مثلًا في نص يستخدم الترميز UTF-32، فنعلم أن لكل حرف مساحة 4 بايت، لا تزيد ولا تنقص، وبالتالي يمكن حساب موقع كل حرف والوصول له مباشرة، فإذا أردنا الوصول للحرف الخامس مثلًا، فنعلم أنه سيبدأ من البايت (4×4 = 16) أي من البايت السابع عشر. أما في حالة الترميز الذي يستخدم مساحة متغيرة، فيجب معالجة كل حرف (كل بايت) للوصول لموقع الحرف المطلوب إيجاده.
لذا فإن ترميز UTF-8 ليس دائمًا الأفضل، خاصة بالنسبة للكثير من الأحرف الآسيوية، فالحرف الصيني المذكور أعلاه مثلًا تطلب 3 بايت في هذا الترميز، بينما يتطلب 2 بايت فقط في ترميز UTF-16. والسبب؟
ﻷنه يشكل 16 بت في النظام الثنائي، وهذا يمكن تمثيله مباشرة كما هو في ترميز UTF-16 بدون سوابق، أما في UTF-8 فبوجود السوابق لن يتسع في 2 بايت.
لذا، وعلى الرغم من الاستخدام الواسع جدًا لترميز UTF-8 وخاصة على الإنترنت، مايزال ترميز UTF-16 مستخدمًا في العديد من أنظمة التشغيل وقواعد البيانات ولغات البرمجة. وماتزال مشكلة اختلاف الترميز تحدث عند إرسال ملف نصي من نظام تشغيل لآخر (من ويندوز للينكس مثلًا).
النص الذي تقرأه الآن يستخدم ترميز UTF-8، فهو الأكثر شيوعًا في الوب كما ذكرت لك. وحيث نضع بشكل صريح في بداية كود صفحات الوب أننا نريد هذا الترميز، فإذا ذهبت للكود المصدري لهذه الصفحة عبر متصفحك، فستجد سطرًا في بداية الكود يدل على ذلك.
إن فكرة المساحة المتغيرة ووضع سابقة لها ليست جديدة عليك. من الأمثلة على الطول المتغير والذي يستخدم سابقة هي أرقام الهواتف الدولية، حيث يختلف عدد أرقام الهاتف من دولة ﻷخرى، ويسبق جميعهم سابقة هي رمز الدولة (963+ لسوريا و 966+ للسعودية وما إلى ذلك). تُعطيك بعض البرامج خطأ في حال إدخالك لعدد أرقام أكثر أو أقل من عدد أرقام الهواتف المتاحة في بلدك، وتعرف البرامج المساحة (عدد الأرقام) الصحيح من السابقة المُدخلة (رمز الهاتف الدولي).
ترتيب البايتات Byte ordering
نكتب في نظامنا العشري العدد 1453 ونقرؤه ألف وأربعمائة وثلاثة وخمسون..جميل. ولكن هل لاحظت أننا بدأنا القراءة من اليسار؟ وهل في لغتنا العربية نبدأ القراءة من اليمين أم من اليسار؟ إذًا لماذا نكتب الأرقام من اليسار لليمين؟ لماذا لا نكتب العدد السابق بالشكل 3541؟
لست هنا ﻷجيبك على هذا السؤال، وإنما ﻷخبرك بأن حاسوبك يستخدم الشكل الأخير!
ما نفعله في العادة في نظام العد العشري الخاص بنا، وهو كتابة وقراءة الأرقام من اليسار لليمين، يسمى في لغة الحاسوب Big Endian أي ذو النهاية الكبرى، حيث يتم حفظ أول بايت في النظام الثنائي (يسارًا) بدايةً في الذاكرة، أي في العنوان الأخفض من الذاكرة (حيث تعطى العناوين بترتيب تصاعدي كالمعتاد)، ثم يتم حفظ مايليه وهكذا. أما الترتيب Little Endian فيتم حفظ البايت الأول يسارًا في الأخير أي في العنوان الأعلى من الذاكرة، يوضح الشكلين التاليين الفرق (حيث نمثل الذاكرة بحجرات تبدأ من الأعلى للأسفل):
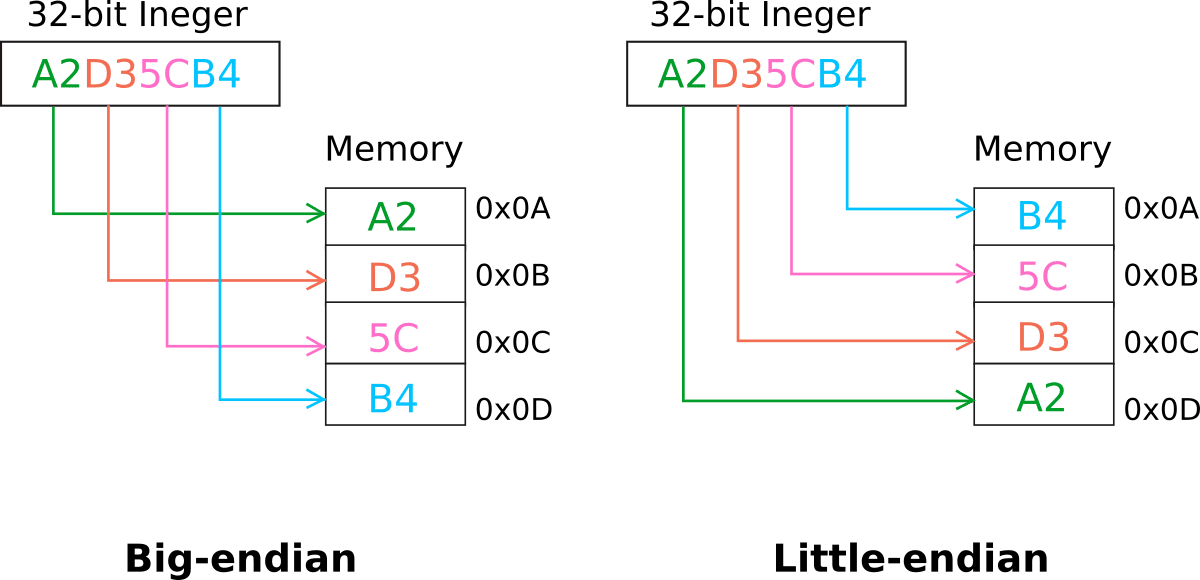
هذا يعني أن العدد الذي ذكرناه بدايةً، وهو 1453، يحفظ في الذاكرة كما هو، أي 1 أولًا ثم 4 ثم 5 ثم 3، وذلك وفق ترتيب big endian، أما وفق ترتيب little endian فيُحفظ الرقم 3 أولًا ثم 5 ثم 4 ثم 1. وسيصبح في الذاكرة بالشكل 3541 إذا اعتبرنا أن اليسار هو العنوان الأخفض من الذاكرة.
إذا نظرنا في مزايا كل ترتيب، فقراءة العدد في النظام الثنائي بالشكل الذي تعلمناه سابقًا، أي بدءًا من اليسار، يتيح لنا مباشرةً ومن أول بت معرفة إشارة العدد إذا كان سالبًا أو موجبًا، والمقارنة كذلك تكون أسهل لمعرفة العدد الأكبر بين عددين. أما قراءة العدد بدءًا من اليمين فيتيح لنا مباشرةً معرفة فيما إذا كان العدد فردي أو زوجي.
لاحظ أننا عندما نريد جمع عددان مع بعضهما بالطريقة اليدوية وهي وضع العددان أسفل بعضهما وحساب الناتج أسفل منهما، نقرأ الأعداد في تلك الحالة ونحسبهم من اليمين لليسار، أي نستخدم عندها Little Endian. لذا فالطريقة هذه أسهل لإجراء الجمع والطرح في الحاسوب. وربما هذا ما يفسر استخدام حواسيبنا الحديثة اليوم لترتيب Little Endian.
من المفيد أن تعلم هنا أن خاصية ترتيب البايتات عمومًا هي خاصية متعلقة بالمعالجات (CPUs) ولا علاقة ﻷنظمة التشغيل بها.
وفي حين أن حواسيبنا اليوم تستخدم Little Endian، يكون الترتيب المعتمَد في الشبكات وعند إرسال البيانات بين الأجهزة على شبكة الإنترنت هو Big Endian (البايت الأعلى قيمة يتم إرساله أولًا)، وتجري عملية التحويل في حاسوبك (الذي يستخدم Little Endian) بين الترتيبين بشكل مستمر.
ولكن لماذا يتم العمل وفق ترتيب Big Endian على الإنترنت؟
لا يوجد سبب! المهم في الموضوع هو توحيد الترتيب على الإنترنت، وقد تم الاتفاق على أن يوحدوه على ذلك الترتيب.
عمومًا، قد لا يهمك موضوع الترتيب كثيرًا، إلا في حالة عملك مثلًا في برمجة الأنظمة المضمَّنة (embedded systems)، أي برمجة الأنظمة التي يتم تضمينها في الغسالات (مثلًا)، وفي أجهزة “إنترنت الأشياء IoT” مثل أجهزة إنذار الحرائق والإضاءة الذكية وغيرها، وكذلك أجهزة أردوينو Arduino وراسبيري باي Raspberry pi، عندها يصبح هذا الموضوع مهمًا، فقد يستخدم المعالج في ذلك الجهاز ترتيب مختلف ويجب عندها فهم ومراعاة ذلك. دعنا الآن نتحدث عن ترتيب البايتات قليلًا في ترميز UTF-16، وذلك عبر المثال أدناه (يُقرأ الجدول من اليسار لليمين):

وكما تلاحظ، يبقى ترتيب البتات ضمن البايت الواحد كما هو، والذي يختلف هو تبديل مواقع كل بايتان متتابعان مع بعضهما البعض. ويظهر ذلك ربما بشكل أوضح في التمثيل الست عشري الظاهر في الجدول كذلك. وسبب التبديل بهذه الطريقة هو أن ترميز UTF-16 يتعامل مع بايتان بايتان كما تعلمنا. أما في ترميز UTF-32 والذي يتعامل مع كل 4 بايتات معًا، فيتم قلب مواقع البايتات الأربعة بالكامل، كما ترى أدناه:

علمًا أن ترميز UTF-32 نادر الاستخدام هذه الأيام.
أما بالنسبة لترميز UTF-8 فلا يوجد له ترتيب مختلف، أي فقط الذي تعلمناه. ﻷن السابقة في البايت الأول هي التي تحدد كم بايت يستخدم ذلك الحرف، لذا يجب أن يتم قراءته أولًا، وبالتالي أي اختلاف في الترتيب سيجعل الترميز غير صالح أصلًا وليس ترميز UTF-8.
ولكن كيف يعرف الحاسوب الترتيب المستخدم في الملف؟
لنشاهد المقطع التالي:
من المفيد أن نعلم أن المحرر النصي لا يقوم بالضرورة بعملية التحويل المذكورة بآخر المقطع، بل يستدعي في الخلفية أدوات مخصصة لذلك.
ولقد ذكرت لك أن عملية تحديد موضع حرف معين في النص عملية صعبة في الترميزات التي تستخدم مساحة متغيرة. وعلى الرغم من ذلك، فلا تشعر أنت بأي بطء أو إشكالية بتغيير موضع المؤشر في المحرر النصي من كلمة لكلمة ومن سطر ﻵخر. فهل أدركت الآن أن المحرر النصي، ذلك البرنامج الذي كنا نعده بسيطًا، يتطلب الكثير من الجهد لصناعته، لنتمكن نحن في النهاية من التعامل مع النصوص بشكل بسيط وسلس جدًا؟.
وفي ختام هذه الفقرة، إعلم أنه يوجد ترتيبات أخرى للبايتات غير Big endian و Little endian. ولكننا تعلمنا هنا الأكثر شيوعًا وأعتقد أن هذا يكفي :).
تمرين
إذا علمت أن التمثيل الست عشري للقلب الأخضر 💚 في ترميز UTF-16 هو d83ddc9a. وباعتبار أن التمثيل هذا معطى بترتيب Big Endian، فما هو التمثيل الست عشري وفق ترتيب Little Endian؟
الجواب في الأسفل.
ترميز مورس Morse code
هو أحد الأنواع القديمة لترميز النص، والتي مازالت تُستخدم في بعض الأجهزة والتطبيقات في يومنا هذا. وُضع من قبل أحد مخترعي التلغراف “ًصامويل مورس”. علمًا أن الترميز المستخدم اليوم يختلف عن النسخة الأولى التي وُضعت سابقًا. حيث تسمى نسخة اليوم بترميز مورس العالمي International Morse code وتحوي الأحرف اللاتينية الـ 26 والأرقام العربية (0-9) وبعض الرموز. ولا تُفرّق بين الأحرف الكبيرة والصغيرة. ويتم الترميز عبر استخدام مجموعة من الخطوط والنقاط، حيث يُعطى كل حرف عدد معيّن من الخطوط والنقاط وبترتيب معيّن. يمكن رؤية ذلك في الجدول التالي الذي يحوي الأحرف والأرقام:

ويتم تمثيل الخطوط والنقاط تلك زمنيًا، حيث أن أصغر وحدة زمنية هي النقطة، ويكون للخط زمنًا 3 أضعاف زمن النقطة. ويشمل الترميز فاصل زمني من السكون لفصل الأحرف عن بعضها. يمكن تمثيل ترميز مورس في الدارات الكهربائية حيث يمثل كل خط ونقطة بنبضات كهربائية وفق الزمن المحدد في الترميز، وكذلك في أمواج الراديو والضوء وكذلك الصوت. ألق نظرة على الرابط أدناه للاطلاع على كيفية تمثيل كل حرف صوتيًا وفق هذا الترميز (ستجد ملف في بداية الصفحة، قم بتشغيله):
https://en.wikipedia.org/wiki/File:A_through_Z_in_Morse_code.ogg
استُخدِم هذا الترميز في أجهزة التلغراف على شكل كهرباء، ثم استُخدم بعد ذلك على شكل موجات صوتية وكذلك إشارات ضوئية. تُستخدم الإشارات الضوئية تلك في يومنا هذا في الطيران وأبراج المراقبة الجوية، بصفتها نظام بديل عن الراديو في حال تعطله.
جواب التمرين أعلاه: 3dd89adc
-
تستخدم بعض التراميز 24 بت أي 3 بايت، يعني أن هذا ممكن. ولكن الترميز الذي نتحدث عنه الآن تم تصميمه بحيث يعطي 32 بت أي 4 بايت لكل حرف ↩︎
-
يمكنك الاطلاع على قائمة اللغات المشمولة في ترميز يونيكود في الصفحة التالية: https://en.wikipedia.org/wiki/Plane_(Unicode) ↩︎